Call Trees in Jupyter Notebooks [LLNL]
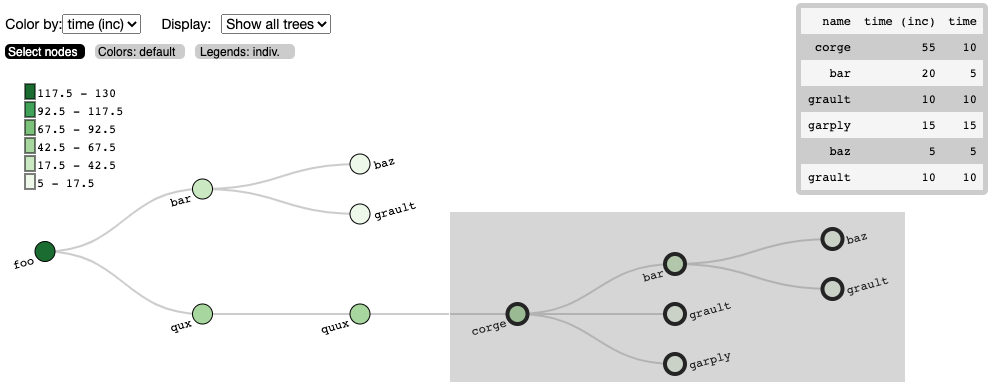
I built an interactive call tree visualization to supplement the Hatchet library.
Mentor: Stephanie Brink
Description: High-performance computer scientists instrument their code at specific areas with Caliper to gather performance data as their code runs, so that they can retroactively look at where slowdowns occurred. Then they open a Jupyter notebook and use the Python-based library called Hatchet to index the dataframes of their performance data and graph data. The users also want to see a representation of the calling context tree of the program (shown here on the left), which is an output that shows how functions called other functions and how long each function took to execute. To supplement the current terminal-like tree visualization in Hatchet from the previous slide, I built an interactive tree that gives users a way to explore the call tree and extract subtrees from the visualization back into the Jupyter notebook cells using Roundtrip.
Papers
S. Brink, I. Lumsden, C. Scully-Allison, K. Williams, O. Pearce, T. Gamblin, M. Taufer, K. E. Isaacs, A. Bhatele, “Usability and Performance Improvements in Hatchet”, 2020 IEEE/ACM International Workshop on HPC User Support Tools (HUST) and Workshop on Programming and Performance Visualization Tools (ProTools), 2020, pp. 49-58, doi: 10.1109/HUSTProtools51951.2020.00013.
Repositories
Hatchet: Hatchet is a Python-based library that allows Pandas dataframes to be indexed by structured tree and graph data. It is intended for analyzing performance data that has a hierarchy (for example, serial or parallel profiles that represent calling context trees, call graphs, nested regions’ timers, etc.).
- My forked version that contains examples of the tree visualizations (under
Roundtrip_Examples/).
Roundtrip: An interface for loading Javascript (notably D3 visualizations) into Jupyter notebooks. Supports transferring data from Python Jupyter cells to Javascript – and back.